


2022年是将人工智能人格化的一年。许多人去年在玩ChatGPT和DALL-E时看到了未来。有些应用非常实用,比如帮助学生更高效的完成作业,或是支持软件工程师调试代码,而另一些应用则更加有趣,例如向ChatGPT询问最新的通心奶酪的食谱,或是与已故的名人聊天。
虽然这些应用对个人消费者和营销工具的升级有强大的发展潜力(Jasper AI 等公司的快速成长就是很好的证明),但是我们不认为在大多数商业应用中仅靠生成式AI会产生巨大的影响。为什么呢?
今天的生成式AI(Generative AI)并不是真正的人工智能,它不是持续准确的,不与结果直接挂钩,也不针对具体语境。这些不足对B2C的应用没有过多的影响,但生成式AI在B2B的应用则需要解决很多现有技术障碍才能实现。
这就意味着生成式AI未来将在解决商业问题上发挥重要的作用。在生成式AI与特定语境模型和人类干预结合后,这项新技术将对今后世界的运作方式产生质的变化。
01
生成式AI具有广泛通用的价值,但风险仍在
生成式AI是帮助我们起草内容的基础性工具,包括文字、图像和代码。无论在个人生活或是工作中,它都可以帮助我们总结提炼信息,节约时间,并提高沟通效率。但是如果我们过于依赖它,生成式AI所提供的不准确甚至是错误的信息会为我们的工作和生活带来很大风险,增添诸多不便。
自2016年以来,人工智能技术一直有类似的潜在风险。我们在《Coaching network(AI教练网络),未来已来》这篇文章中所阐述的观点是基于人类是人工智能时代唯一的变化引擎,这一前提而提出的。生成式AI的未来是基于其基础不断创造发展还是把它的功能停留在参考建议这一层面,取决于我们未来的技术能力和意愿选择。
基于这一背景,生成式AI在商业应用中会遭遇不少难题。
生成式AI缺乏准确性
OpenAI的GPT-3这样的通用大型语言模型(LLM,Large Language Model)被训练得与作家十分相似,但却没被训练的像作家一样精准。这就是为什么ChatGPT可以就拿破仑战争的历史写出一篇令人信服、措辞得体的文章,但它不能确保文章中的所有事件都是真实准确的。此外,由于LLM是在特定时间,通过数据集进行训练,训练结束后发布产品,所以它无法纳入更多的最新数据(例如,GPT-3不包含2021年之后的所有信息)。因此,如果要求它写一篇关于当前乌克兰战争的文章,得出的结果会非常差。
今天的生成式AI只是在模仿它所接受训练过的数万亿字符。因为它的训练模型是基于匹配互联网上的文本,而互联网上的信息并不完全准确,所以导致生成式AI生成的内容不能被完全信任。
Mashable在2022年12月发表了一篇题为 "OpenAI的ChatGPT聊天机器人是惊人的、创造性的、但完全错误的 "文章,文章中列举了ChatGPT在回答基本知识问题时的错误或是利用其想象力凭空捏造信息的情况。虽然这些例子大多风险很低,但可以帮你理解为什么像GPT-3这样的模型在商业中运用会带来很大的风险。这就是为什么《大西洋》杂志认为要 "把ChatGPT当作一个玩具,而不是一个工具"。
现在生成式AI的商业应用大多以市场营销(文案/邮件营销)和广告为目的而调整的,在这些应用中,偶尔的不精准信息通常是可以容忍的。但对于大多数商业场景,准确性至关重要。如果想让企业在更多的使用场景中运用生成式AI,则需要结合更多的语境和人工协助。

生成式AI不以结果为导向
生成式AI是以输出为导向,而不是以结果为导向,这对个人用户来说很有效,但对企业用户来说却不然。ChatGPT可以为一个新的饮料品牌生成广告语,但它不能告诉你哪一个更好。这是因为用户与模型的互动像是一条单行路,它缺乏根据结果不断学习的能力。当涉及到B2B的使用场景时,企业需要的不仅仅是一个生成器。他们需要的是不断迭代,并针对不同行业生成特定结果为驱动的人工智能技术。
未来有发展潜力的生成式AI APP 在B2B的应用将以投资回报为基础。例如,我们的被投企业Ironclad在用人工智能来帮助用户更高效地起草和编辑合同。它的功能不仅能帮助律师更高效的工作,还能帮助他们提高最终结果。它的人工智能平台可以指导合同起草人了解怎样制定条款可以更快的推动交易完成。通过将LLM的建议与平台专有数据相结合,Ironclad正在建立一个合理的、以结果为导向的人工智能产品。
生成式AI应用广泛却缺乏深度
为了解决现有生成式AI的不足,来满足更多的在商业场景中应用,人工智能需要根据公司的特定数据进行训练。现在的语言模型大多是在公开可用的数据上进行训练的,但它们缺乏就不同情境和有知识产权的数据的训练,正式缺少这些非公开数据的训练,影响开发针对B2B用户的功能。例如,如果没有Ironclad工作流程软件中特定的语境数据,仅依靠LLM就不能确定哪个条款可以最快地完成合同。
我们并不看好能使生成式AI真正对B2B应用产生真正价值所需的大量专有数据在未来能与LLMs合成。这是因为企业不愿意与LLMs分享他们最有价值的有知识产权性质的专有数据。企业的竞争优势就在于他们积累的专有数据,这就是为什么企业对于LLMs直接(甚至间接)访问他们的专有数据持谨慎态度。这一担忧源于去年OpenAI、微软和Github对于CoPilot的集体诉讼。机构和大型企业由于担心失去竞争优势,对于把他们的专有数据贡献给分布广泛的模型非常谨慎。因此如果想开发针对B2B的生成式AI软件需要找到另一种方法来解决这个问题。
这种方法可以是外部LLM和内部开发模型和数据集的结合。B2B的应用可以从要求LLM生成初始内容开始。随后这些初始内容被送入一个经过微调的内部开发的模型中,将初始内容进行修改和完善来满足特定B2B应用场景的需求。这些 “小型特定的语言模型”将利用应用程序从中产生或可获得的专有数据建立知识图谱,通过将开源的LLM和专有的SSLM(或建立他们自己的端到端堆栈)连接在一起,B2B软件将会提供强大的且可信的投资回报。
02
下一代AI APPs:从生成到真实
那么在生成式AI的时代,B2B软件的未来将会是怎样的?我们认为,它是利用LLM的通用价值,并将其与客户的专有数据相结合,以产生准确的、与结果挂钩的、依据特有情境的结果。
在未来的几年里,每个行业的每个公司的每个职能都将被改变。你的工作是帮助客户扩展并保护他们核心业务的核心知识产权的同时整合并利用生成式AI的力量。我们认为这意味着要利用LLM的独特属性来建立一个与结果挂钩的应用,但动力模型将不仅仅限于OpenAI或任何其他基础模型。这些LLMs将只提供一部分价值,B2B的生成式AI的未来将会是语言模型与来自人类干预和独创的专有数据的结合。
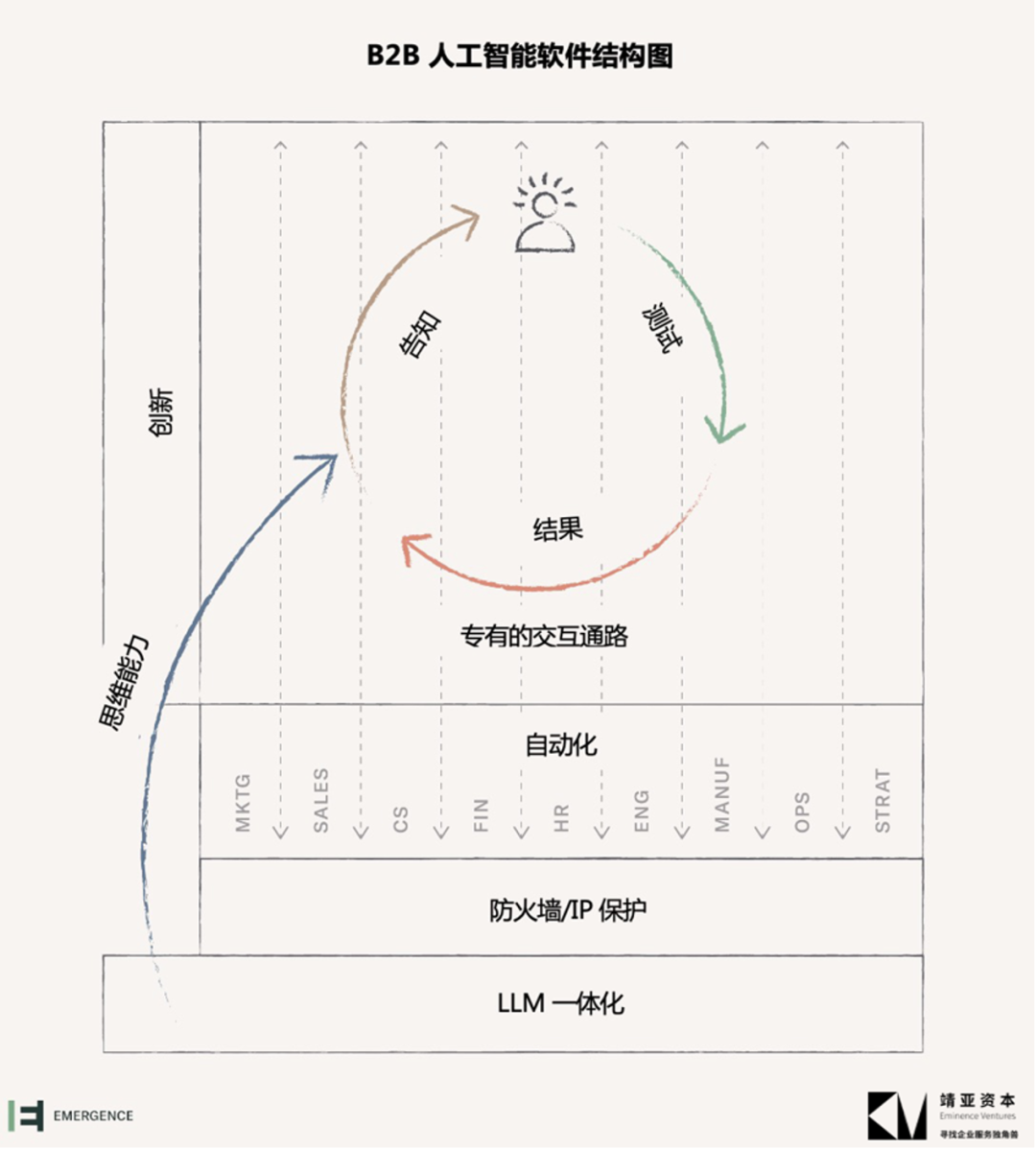
下图展示了B2B人工智能软件结构图,来帮助你构想你想从哪一部分开始进入或关注。
作者:Gordon Ritter,Emergence Capital 创始人,合伙人
Jake Saper, Emergence Capital 合伙人
独家授权编译:靖亚资本
编译:Angela
责编:Emma
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 生成式AI为何不完全适用当下B2B行业?
heng.png)
 达观助手智能写作产品正式发布,全面提升写作能力!
达观助手智能写作产品正式发布,全面提升写作能力! 生成式AI为何不完全适用当下B2B行业?
生成式AI为何不完全适用当下B2B行业? Gartner:ChatGPT只是开始,企业生成式AI的未来
Gartner:ChatGPT只是开始,企业生成式AI的未来 中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国