

过去,人工智能经常被比作石油行业:一旦对(数据 / 石油)进行开采、精炼,就可以变为高利润的商品。现在看来,人工智能在能耗层面的表现也可与石油行业一较高下。根据最新的论文结果,训练一个 AI 模型产生的能耗多达五辆汽车一生排放的碳总量。
这篇 新论文 是马萨诸塞大学阿默斯特校区的研究人员公布的,以常见的几种大型 AI 模型的训练周期为例,发现该过程可排放超过 626,000 磅二氧化碳,几乎是普通汽车寿命周期排放量的五倍(其中包括汽车本身的制造过程)。
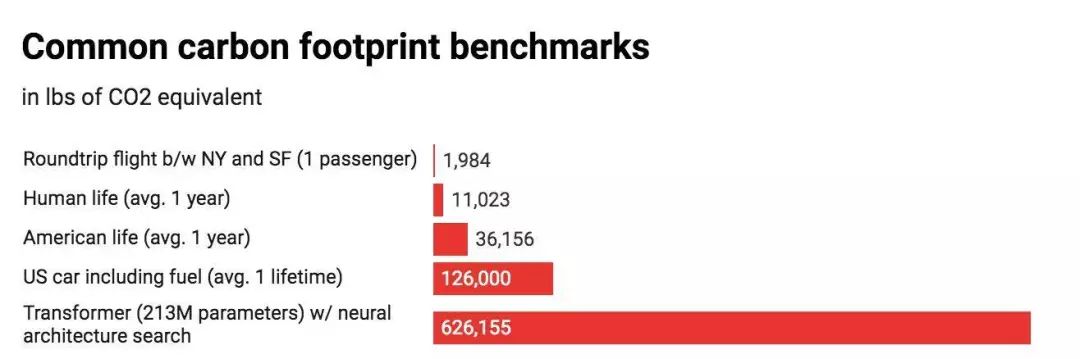
这一结果也是很多 AI 研究人员没有想到的。西班牙拉科鲁尼亚大学的一位计算机科学家表示:“虽然我们中的很多人对此(能耗)有一个抽象的、模糊的概念,但这些数字表明事实比我们想象得要严重。我或者是其他 AI 研究人员可能都没想过这对环境的影响如此之大。”
以自然语言处理为例,研究人员研究了该领域中性能取得最大进步的四种模型:Transformer、ELMo、BERT 和 GPT-2。研究人员在单个 GPU 上训练了至少一天,以测量其功耗。然后,使用模型原始论文中列出的几项指标来计算整个过程消耗的总能量。
结果显示,训练的计算环境成本与模型大小成正比,然后在使用附加的调整步骤以提高模型的最终精度时呈爆炸式增长,尤其是调整神经网络体系结构以尽可能完成详尽的试验,并优化模型的过程,相关成本非常高,几乎没有性能收益。BERT 模型的碳足迹约为 1400 磅二氧化碳,这与一个人来回坐飞机穿越美洲的排放量相当。
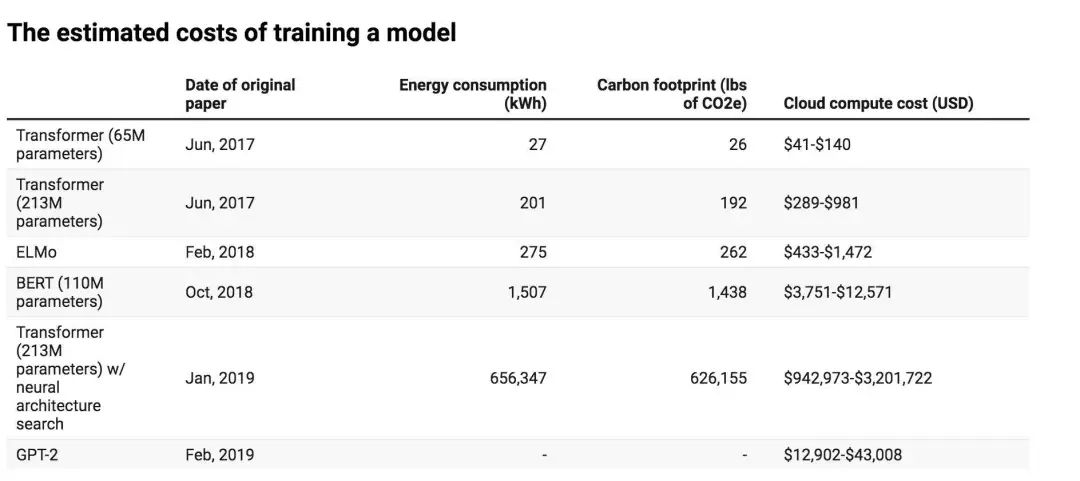
此外,研究人员指出,这些数字仅仅是基础,因为培训单一模型所需要的工作还是比较少的,大部分研究人员实践中会从头开发新模型或者为现有模型更改数据集,这都需要更多时间培训和调整,换言之,这会产生更高的能耗。根据测算,构建和测试最终具有价值的模型至少需要在六个月的时间内训练 4,789 个模型,换算成碳排放量,超过 78,000 磅。
随着 AI 算力的提升,这一问题会更加严重。
这些结果也凸显了 AI 另一个日益严重的问题:产生结果所需的大量资源使学术界工作人员很难继续研究。显然,这种通过大量数据训练庞大模型的趋势对学者尤其是研究生来说并不可行,因为没有资源,这让学术界和工业界的研究人员之间出现公平访问的问题。
抛开环保和能耗本身,人工智能的训练过程同样成本高昂。以机器学习为例,数据、算法、算力成本同样“触目惊心”。
与数据相关的机器学习成本主要表现在数据集方面,包括数据集的获得、数据的标注等。Dimensional Research 代表 Alegion 所做的一项 最新研究 表明,所有组织中的 96%都遇到了与训练数据质量和数量相关的问题。同一项研究表明,大多数项目需要超过 100,000 个数据样本才能表现良好。
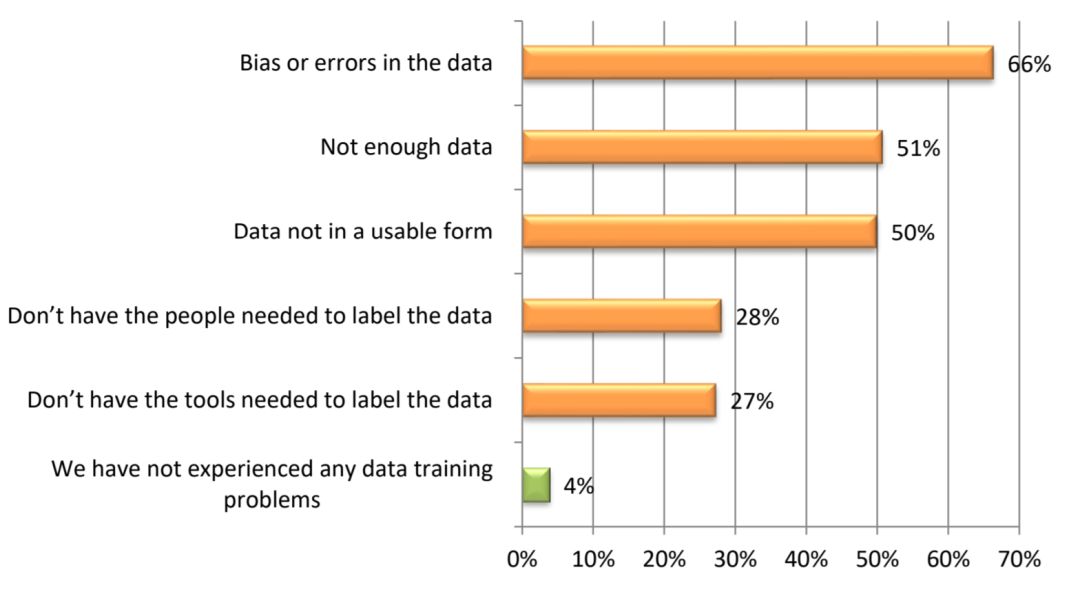
Dimensional Research 研究的图表说明了公司在数据方面面临的最常见问题
如果还没有数据,可以假设能够在大约一个小时内收集 5–10 个样本并对它们进行标注。利用 亚马逊的 Mechanical Turk 之类的服务来实验整个过程,生成 100,000 个样本数据集的话,花费大约为 70,000 美元。
如果已经收集了大量数据,则可以使用 Scale 之类的服务来对其进行标注。在这种情况下,获得 100,000 个带有标签的数据样本,则可能需要花费 8,000 到 80,000 美元的费用,具体的需要取决于标注的复杂程度。
此外,检查和校正数据样本与生成和注释数据样本一样耗时。Dimensional Research 研究报告中提到,66%的公司在其数据集中遇到偏差和错误问题。有些公司选择采用完整的内部方法(自己做所有标注),也有一些公司会选择外包和内部混合使用。第二种常见的情况是将大部分工作外包,然后由个别人员负责验证和清理。外包 10 万个数据样本的初始成本可能会增加大约 2500 至 5,000 美元。
Dimensional Research 报告指出,大多数企业 AI 团队的成员不足 10 名。假设每个技术团队有 5 名成员,其中 3 个是外包。在这种配置下,团队可能足以并行处理两个项目,平均每 1.5 个月研究一个项目。基于此的成本是 2 名员工(2 x 5,000 美元),3 名自由职业者(3 x 3,000 美元),每月的总成本是 19,000 美元。如果团队可以同时处理两个项目,并且研究时间为 1.5 个月,则意味着该阶段的成本约为每个项目 14,250 美元。
与算力相关的机器学习成本主要表现在基础架构、集成、维护以及各种处理器的功耗方面。
生产成本包括基础架构成本(云计算,数据存储),集成成本(数据管道开发,API 开发,文档)和维护成本。
其中,云计算的支出取决于部署算法的复杂性。如果模型不是很深,并且是在低维表格数据上进行训练,则将获得 4 个虚拟 CPU 运行在 1 到 3 个节点上的服务,每月费用为 100 到 300 美元,即每年 1200 到 3600 美元。另一方面,对于无延迟的深度学习推理,价格从 10,000 美元到 30,000 美元不等。
集成可能比较棘手。在大多数情况下,只需要将 API 端点放在云中并记录下来,供系统的其余部分使用即可,准备要使用的机器学习模型并编写 API 脚手架最多需要 20 到 30 个开发小时,其中包括测试,成本约为 1,500 美元,加上修改系统的其余部分以使用新 API 所需的成本。稳定的数据管道将花费更多的时间,大概需要 80 个小时左右。
迄今为止,实施 AI 的最大成本是落地。太多人着迷于 ML 和 AI,并将其开发预算投入到追求该技术而不是解决实际问题上。我们正处于机器学习仍然是一项高度实验性技术的阶段,其成功率差异很大。Garter 预测,到 2022 年,将有 85%的 AI 项目交付错误的结果。
玩不起系列:成本总和
除去附加项成本和一系列功耗所带来的成本,机器学习项目可能会使公司花费 51,750 美元至 136,750 美元(不包括难以确定的其他成本)。高差异是由数据的性质决定的。这是一个非常乐观的估计。如果企业位于美国,并且使用的是明智的数据(自由职业者不会这样做),则与人才相关的费用将激增,使 ML 项目的费用超过 108,500 美元。
这样高昂的价格使想要解决新问题或自动化其流程和决策的个人、小型团队和初创企业无法使承担。最艰难的步骤是第一步:获取数据。没有数据,几乎不可能在研究阶段验证机器学习解决方案,从而导致几乎死锁。
综上,这些因素都可能会导致人工智能研究的私有化。对此,一位大数据和人工智能领域的技术专家在接受 InfoQ 采访时表示,BERT 模型其实可以解决一部分数据问题,因为要达到同样的效果,它需要的数据量相对较小,但算力确实是很难攻破的问题,这也就意味着 硬件成本很难下降。目前,一种可行的解决方式是通过租用云端 TPU 的方式来降低成本,但人工智能逐渐趋于私有化确是事实,未来学术界将在非强依赖算力的领域有更多创新,工业界由于尚可承担算力提升带来的各种成本,会在强依赖算力的领域有更多突破,这将实现学术界与工业界的合理分工。
特别声明:
文章来源:AI前线(ai-front)
作者: 张之栋、赵钰莹
原文链接:https://mp.weixin.qq.com/s/xEUt46vZMEXOYiRqYmZodA
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 触目惊心:AI到底消耗了多少能源和成本?
heng.png)
 达观助手智能写作产品正式发布,全面提升写作能力!
达观助手智能写作产品正式发布,全面提升写作能力! 生成式AI为何不完全适用当下B2B行业?
生成式AI为何不完全适用当下B2B行业? Gartner:ChatGPT只是开始,企业生成式AI的未来
Gartner:ChatGPT只是开始,企业生成式AI的未来 中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国