

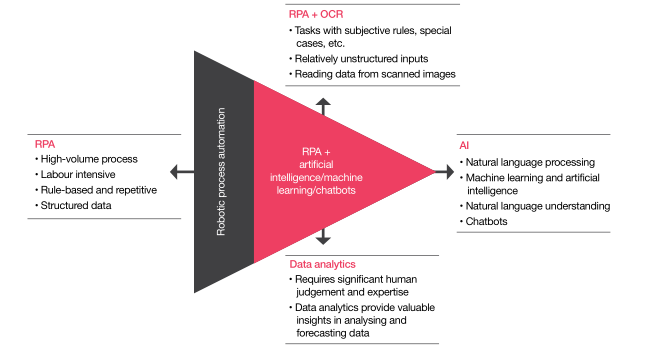
目前,全球各个行业都在谋求数字化转型,以便更好的应对数字化经济潮流,而RPA正成为其重要的转型工具。随着企业业务的多元化发展,多数已不仅仅满足于传统的自动化业务,开始转向IPA(智能自动化)。
IPA是指将RPA与多种主流人工智能技术如OCR(光学字符识别)、ML(机器学习)、NLP(自然语言处理)等相结合的新型智能自动化。将帮助组织更好的处理那些非结构化数据任务,并且极大地提高工作效率和提升数据的准确性。

在多数组织的智能自动化流程业务中,OCR是应用最多的人工智能技术之一。OCR与RPA的结合可以将组织中超过70%的无纸化业务实现自动化,其效率将是人工的5倍以上。下面本文将详细介绍OCR与RPA在智能自动化中的一些案例和注意事项。
什么是OCR?它是如何工作的?
OCR是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机数据的过程。
针对印刷体字符,采用光学的方式将纸质文档中的文字转换成为黑白点阵的图像文件,并通过识别软件将图像中的文字转换成文本格式,供文字处理软件进一步编辑加工的技术。衡量一个OCR系统性能好坏的主要指标有:拒识率、误识率、识别速度、产品的稳定性、易用性等。
ICR与OCR的区别
OCR和ICR的核心区别在于: OCR其功能仅限于识别看起来相同的字符,而ICR是将传统字符识别与机器学习进行深度融合,可以从非标准文档中解析数据,有助于将手写文本字符转换为机器可读的格式。
OMR(光学标记识别):
该技术有助于识别带有刻度线、复选标记以及下划线的字符。OMR的特点是阅读准确(即对涂点的识别有极高的精确度,误码率小于千万分之一)、 阅读速度快,每秒钟可以处理一千多个信息点。
OBR (Optical barcode reader):
OBR主要用于读取文档中的条形码数据。
上述的这些识别技术主要用于日常工作的数据识别和提取。下面将介绍一些实际的案例。
半结构化文件:
半结构化文档没有正式的数据结构。该文档通常是相同的,但是设计和布局可能会有所不同。信息将被标记在文档中,但是信息的位置可能因文档而异。常见的半结构化文档识别案例有发票提取和整理,采购订单的识别等。在OCR识别半结构化文件后,将其转化成结构化数据,然后再交由RPA做进一步的自动化处理。
非结构化数据:
非结构化数据是数据结构不规则或不完整,没有预定义的数据模型,不方便用数据库二维逻辑表来表现的数据。包括所有格式的办公文档、文本、图片、XML,HTML、各类报表、图像和音频/视频信息等等。
非结构化数据在任何地方都可以得到。这些数据可以在你公司内部的邮件信息、聊天记录以及搜集到的调查结果中得到,也可以是你对个人网站上的评论、对客户关系管理系统中的评论或者是从你使用的个人应用程序中得到的文本字段。或者是在公司外部的社会媒体、你监控的论坛以及来自于一些你很感兴趣的话题的评论。

企业哪些业务需要OCR?
多数情况下,OCR主要用于简化纸质业务并将其转化成数字化业务,例如:PDF、扫描文件、纸质发票、传真和手写文档等。
适用的行业包括:
-
金融行业:员工入职、客户开户、贷款申请、数据校审等。
-
制造行业: 订单处理、汇款、仓库盘点等。 -
人力资源: 员工入职、筛选简历、人力资源记录处理等。 -
供应链管理: 订单和货运跟踪、提货单、货物订单等。
当OCR用于图像识别提取数据时,需要注意哪些事情?
-
需要高清图片:大多数市场上的OCR引擎对图像质量都有着最低要求。通常图像每寸的DPI要求在200—300之间,如果可以提供500以上DIP图像,这将极大地提高OCR的识别效率和准确率。
-
尽量不要手写文本:一些业务流程如制造商审批、数据审计、检查员签字时可能需要手写签字。但是手写文本的形体等原因,会降低文档的质量影响OCR的识别效率。
-
不要扫描副本文件:有的时候在打印和扫描图片时,会扫描副本文件,这将影响图片的质量从而影响OCR的提取效率。
-
使用纯白背景:通常业务文档包含很多设计元素,如纹理、背景图像等。这将严重阻碍OCR的识别。
-
保持规定格式:一般情况下OCR的识别格式比较广泛,包括:TXT、EML、XLSX、VSD、HTML、DOCX、XLS、VSDX、DOC、PPTX、HTM、PPT、RTF、BMP、PCX、DCX、JPEG、TIFF、GIF、PNG、PDF等格式。尽量不要提供这些格式以外的文件,否则将造成无法识别。
下面这个实例将帮助大家更好的理解RPA与OCR的工作原理:
1、用户收到一封带有图片的电子邮件。
目前全球的RPA厂商正在通过与不同的人工智能技术相结合,来提升竞争力赢得市场。而OCR在频率、业务范围、以及对业务影响上都领先于其他技术。通过OCR来处理那些非结构化业务,也使得RPA的自动化范围可以扩展到更多的领域中。
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 详解RPA与OCR的工作机制与原理
heng.png)
 RPA CoE x GPT = 未来企业
RPA CoE x GPT = 未来企业 RPA技术的进阶之路:智能化、多元化与增强发展
RPA技术的进阶之路:智能化、多元化与增强发展 没钱没需求,企业数字化转型怎么干?
没钱没需求,企业数字化转型怎么干? 从ChatGPT数据泄露事件,看组织安全稳定自动化的重要性
从ChatGPT数据泄露事件,看组织安全稳定自动化的重要性
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国