

编者按:近年大热的机器人流程自动化(Robotic Process Automation, RPA)利用 AI 技术将人们从繁杂的电子文档处理任务中解放出来,其中最关键就是自动文档分析与识别技术。面对大量无标注电子文档,现有的大规模预训练语言模型能够在预训练阶段有效捕捉文本中蕴含的语义信息,但忽视了文档中的视觉结构信息。微软亚洲研究院近日发布了结合文档结构信息和视觉信息的通用文档预训练模型 LayoutLM,在表单理解、票据理解、文档图像分类等任务的测试中均取得了目前的最佳成绩,模型、代码和论文都已开放下载。
随着许多行业的数字化转型,电子商业文档的结构化分析和内容提取成为一项热门的研究课题。电子商业文档通常包括两大类:一类是纸质文档的扫描图像件,另一类是计算机生成的数字文档,这些文档涵盖采购单据、行业报告、商务邮件、销售合同、雇佣协议、商业发票、个人简历等。
一般来说,电子商业文档包含了公司对于内部和外部事物的处理细节,具有大量与行业相关的实体信息和数字信息。在过去,电子商业文档的信息处理一般由人工来完成,然而,人工信息提取不仅耗时费力,可复用性也不高,大大限制和阻碍了企业运行效率。因此,电子文档的自动精准快速处理对于企业生产力提升至关重要,这也促使了一些新兴行业的出现,帮助传统行业进行数字化转型,提高生产力。
近年来,机器人流程自动化(Robotic Process Automation, RPA)应运而生,正是利用人工智能技术帮助大量人力从繁杂的电子文档处理任务中解脱出来,提供了一系列配套的自动化工具提升企业生产力。其中,最为关键的核心技术就是自动文档分析与识别技术。
传统的文档分析和识别技术往往基于人工定制的规则或少量标注数据进行学习,这些方法虽然能够带来一定程度的性能提升,但由于定制规则和可学习的样本数量不足,其通用性往往不尽如人意,针对不同类别文档的分析迁移成本较高。
随着深度学习预训练技术的发展,以及大量无标注电子文档的积累,文档分析与识别技术进入了一个全新的时代。大量的研究成果表明,大规模预训练语言模型能够通过自监督任务在预训练阶段有效捕捉文本中蕴含的语义信息,经过下游任务微调后能有效地提升模型效果。然而,现有的预训练语言模型主要针对文本单一模态进行,而忽视了文档本身与文本天然对齐的视觉结构信息。
为了解决这一问题,我们提出了一种通用文档预训练模型 LayoutLM,对文档结构信息(Document Layout Information)和视觉信息(Visual Information)进行建模,让模型在预训练阶段进行多模态对齐。我们在三个不同类型的下游任务中进行验证:表单理解(Form Understanding),票据理解(Receipt Understanding),以及文档图像分类(Document Image Classification)。
实验结果表明,我们在预训练中引入的结构和视觉信息,能够有效地迁移到下游任务中。最终在三个下游任务中都取得了显著的准确率提升,具体来说:
1)在表单理解任务中,我们的方法相比较于仅使用文本预训练的模型提升8.5个百分点;
2)在票据理解任务中,我们的方法比ICDAR 2019票据信息抽取比赛第一名的方法提升1.2个百分点[1];
3)在文档图像分类任务中,我们的方法比目前公开发表的最好结果提升1.3个百分点[2]。
目前,预训练模型和代码都已经开放下载:
-
代码链接:
https://github.com/microsoft/unilm/tree/master/layoutlm
-
论文链接:
https://arxiv.org/abs/1912.13318
文档结构信息
很多情况下,文档中文字的位置关系蕴含着丰富的语义信息。以下图的表单为例,表单通常是以键值对(key-value pair)的形式展示的(例如“DATE: 11/28/84”)。通常情况下,键值对的排布通常是左右或者上下形式,并且有特殊的类型关系。类似地,在表格文档中,表格中的文字通常是网格状排列,并且表头一般出现在第一列或第一行。通过预训练,这些与文本天然对齐的位置信息可以为下游的信息抽取任务提供更丰富的语义信息。

图1:图像文档样例
视觉信息
对于富文本文档,除了文字本身的位置关系之外,文字格式所呈现的视觉信息同样可以帮助下游任务。对文本级(token-level)任务来说,文字大小,是否倾斜,是否加粗,以及字体等富文本格式能够体现相应的语义。通常来说,表单键值对的键位(key)通常会以加粗的形式给出。对于一般文档来说,文章的标题通常会放大加粗呈现,特殊概念名词会以斜体呈现等。对文档级(document-level)任务来说,整体的文档图像能提供全局的结构信息。例如个人简历的整体文档结构与科学文献的文档结构是有明显的视觉差异的。这些模态对齐的富文本格式所展现的视觉特征可以通过视觉模型抽取,结合到预训练阶段,从而有效地帮助下游任务。
为了建模上述信息,我们需要寻找这些信息的有效表示方式。然而现实中文档格式丰富多样,除了格式明确的电子文档外,还有大量扫描式报表和票据等图片式文档。对于计算机生成的电子文档,我们可以使用对应的工具方便地获取文本和对应的位置以及格式信息。而对于扫描图片文档,我们使用 OCR 技术进行处理,从而获得相应的信息。通过两种不同的手段,我们几乎可以使用现存的所有文档数据进行预训练,保证了预训练数据的规模。
为了利用上述信息,我们在现有的预训练模型基础上添加 2-D Position Embedding 和 Image Embedding 两种新的 Embedding 层,这样一来可以有效地结合文档结构和视觉信息。
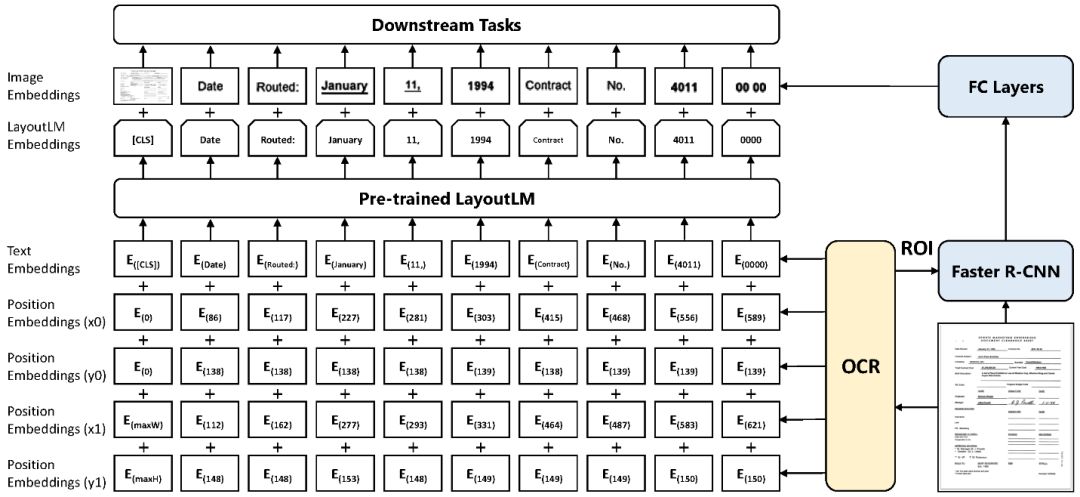
图2:LayoutLM 模型结构图
2-D Position Embedding
根据 OCR 获得的文本 Bounding Box,我们能获取文本在文档中的具体位置。将对应坐标转化为虚拟坐标之后,我们计算该坐标对应在 x、y、w、h 四个 Embedding 子层的表示,最终的 2-D Position Embedding 为四个子层的 Embedding 之和。
Image Embedding
在 Image Embedding 部分, 我们将每个文本相应的 Bounding Box 当作 Faster R-CNN 中的候选框(Proposal),从而提取对应的局部特征。特殊地,由于 [CLS] 符号用于表示整个输入文本的语义,我们同样使用整张文档图像作为该位置的 Image Embedding,从而保持模态对齐。
在预训练阶段,我们针对 LayoutLM 的特点提出两个自监督预训练任务:1)Masked Visual-Language Model(MVLM,遮罩式视觉语言模型)2)Multi-label Document Classification (MDC,多标签文档分类)。
任务1:MVLM 遮罩式视觉语言模型
大量实验已经证明 MLM 能够在预训练阶段有效地进行自监督学习。我们在此基础上进行了修改:在遮盖(Mask)当前词之后,保留对应的 2-D Position Embedding 暗示,让模型预测对应的词。在这种方法下,模型根据已有的上下文和对应的视觉暗示预测被遮罩的词,从而让模型更好地学习文本位置和文本语义的模态对齐关系。
任务2:MDC 多标签文档分类
MLM 能够有效的表示词级别的信息,但是对于文档级的表示,我们需要文档级的预训练任务来引入更高层的语义信息。在预训练阶段我们使用的 IIT-CDIP 数据集为每个文档提供了多标签的文档类型标注,我们引入 MDC 多标签文档分类任务。该任务使得模型可以利用这些监督信号去聚合相应的文档类别,并捕捉文档类型信息,从而获得更有效的高层语义表示。
预训练过程
预训练过程我们使用 IIT-CDIP 数据集[3]。IIT-CDIP 数据集是一个大规模的扫描图像公开数据集,经过处理后文档数量达到约11,000,000。我们随机采样了1,000,000进行了测试实验,最终使用全量数据进行完全预训练。
通过千万文档量级的预训练并在下游任务微调,我们在测试的三个不同类型的下游任务中都取得了目前的最佳成绩:在 FUNSD 数据集上将表单理解的 F1 值从70.72提高至79.2;将 ICDAR 2019 票据理解 SROIE 比赛中的第一名成绩94.02提高至95.24;在 RVL-CDIP 文档图像分类数据集上将目前的最好结果93.07提高至94.42。
表单理解(Form Understanding)
在表单理解任务上,我们使用 FUNSD 作为测试数据集,该数据集中的199个标注文档包含31,485个词和9,707个语义实体。在该数据集上,我们需要对数据集中的表单进行键值对(key-value)抽取。通过引入位置信息的预训练,我们的模型在该任务上取得了显著的提升。实验结果见下表。
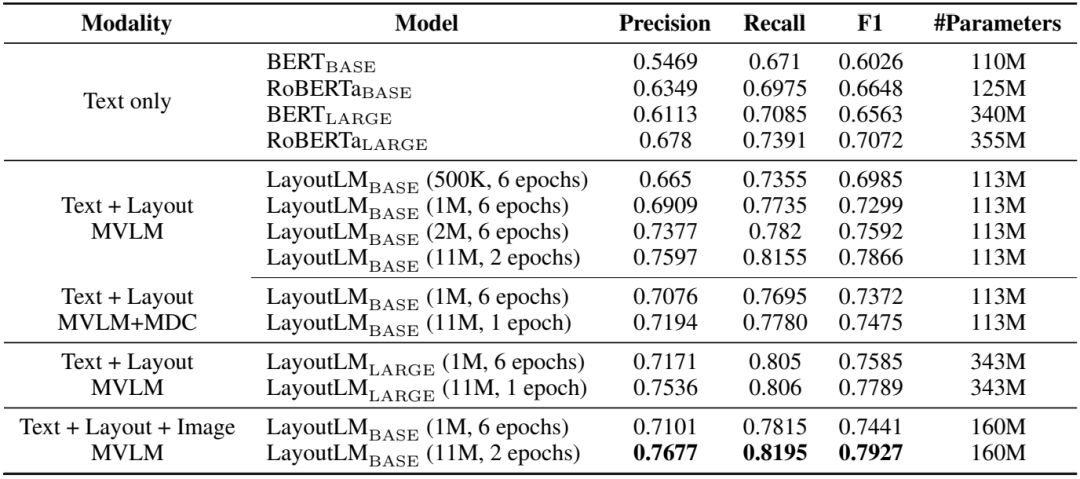
表1:LayoutLM 在 FUNSD 数据集上的实验结果
票据理解(Receipt Understanding)
在票据理解任务中,我们选择 SROIE 测评比赛作为测试。SROIE 票据理解包含1000张已标注的票据,每张票据标注了店铺名、店铺地址、总价、消费时间四个语义实体。通过在该数据集上微调,我们的模型在 SROIE 测评中,F1 值高出第一名(2019)1.2个百分点,达到95.24%。

表2:LayoutLM 在 SROIE 测评上的实验结果

图3:SROIE 测评排名情况[4] (截至2020年3月)
文档图像分类(Document Image Classification)
对于文档图像分类任务,我们选择 RVL-CDIP 数据集进行测试。RVL-CDIP 数据集包含16类总记40万个文档,每一类都包含25,000个文档数据。我们的模型在该数据集上微调之后将分类准确率提高了1.35个百分点,达到了94.42%。

表3:LayoutLM 在 RVL-CDIP 数据集上的实验结果
我们同样根据实验设置进行了分析。根据对训练数据、步长、模型结构和初始化结构的分析,LayoutLM 还有更多的潜力可以挖掘。
训练数据及步长
根据下表,我们可以看到增加训练数据和训练步长都能显著提高模型效果。
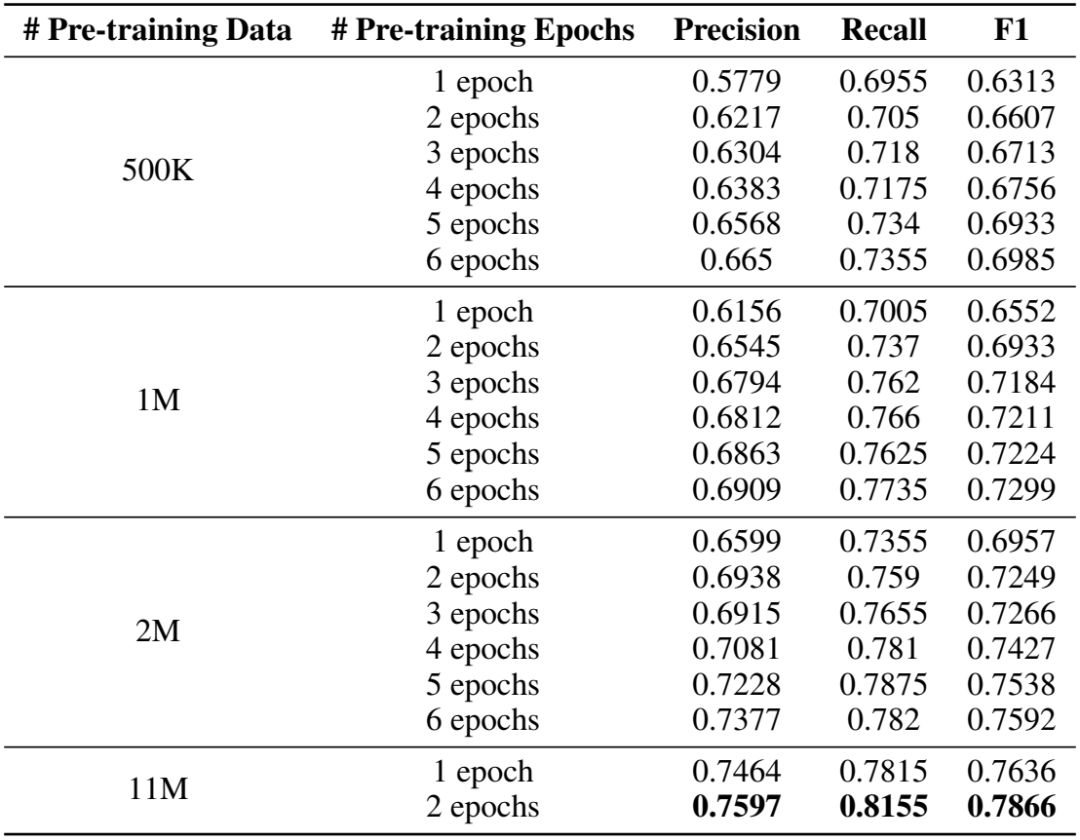
表4:不同训练步长和数据量情况下 LayoutLM 在 FUNSD 数据集上的实验结果对比
模型结构和初始化权重
我们进行了使用 BASE/LARGE 网络结构以及使用 BERT/RoBERT 权重初始化的对照实验。根据实验结果我们发现,在其他实验设置相同的情况下,使用规模更大的网络结构和更有效的权重能显著影响模型的效果。

表5:不同权重初始化和不同网络规模情况下 LayoutLM(Text+Layout, MVLM)在 FUNSD 数据集上的实验结果对比
经过实验,我们观察到在文档内容理解任务中,通过在预训练阶段引入文档结构和视觉信息能有效提高模型在下游任务的表现。未来的工作中,我们将会在预训练阶段尝试将 Image Embedding 进行早期融合(Early Fusion),将图像信息编码进 LayoutLM。与此同时,我们也会尝试其他有效的预训练任务,同时引入规模更大的训练数据,扩展 LayoutLM 的潜力。
我们已经放出论文以及预训练模型,并提供了微调的代码样例,更多信息请访问以下链接。
论文链接:
https://arxiv.org/abs/1912.13318
代码链接:
https://github.com/microsoft/unilm/tree/master/layoutlm
参考文献:
[1] https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=3
[2] https://paperswithcode.com/sota/document-image-classification-on-rvl-cdip
[3] https://ir.nist.gov/cdip/
[4] https://rrc.cvc.uab.es/?ch=13&com=evaluation&task=3
特别声明:
文章来源:微软研究院AI头条
原文链接:https://mp.weixin.qq.com/s/bK4hoxiw--pfqtAduduIZw
RPA中国推荐阅读,转载此文是出于传递更多信息之目的。如有来源标注错误或侵权,请联系更正或删除,谢谢。
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 赋能RPA时代,微软发布通用文档理解预训练模型LayoutLM
heng.png)
 为何说数字化的本质就是自动化
为何说数字化的本质就是自动化 科技爆炸,白领办公新style,工作吩咐一声,电脑自动完成
科技爆炸,白领办公新style,工作吩咐一声,电脑自动完成 如何通过人工智能和自动化提高供应链弹性?
如何通过人工智能和自动化提高供应链弹性? 经济萧条下,RPA投入应该被“牺牲”掉吗?
经济萧条下,RPA投入应该被“牺牲”掉吗?












热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国