

近日,Uber宣布开源其AI模型调试工具Manifold,这是一款与模型无关的可视化调试工具,可帮助工程师和科学家跨ML数据切片和模型识别潜在问题,并通过显示数据子集之间的特征分布差异来诊断其根本原因。

通常当数据科学家开发AI模型时会使用汇总得分,例如:对数损失、曲线下面积(AUC)和平均绝对误差(MAE)来评估每个候选AI模型。尽管这些指标提供了有关模型执行情况的见解,但它们并未传达有关模型执行不佳的原因,以及如何改善模型性能的大量信息。
因此,模型构建者在确定如何改进其模型时倾向于依靠反复试验。为了使模型迭代过程更明智和可操作,Uber开发了Manifold用于ML性能诊断和模型调试。利用可视化分析技术,Manifold使ML从业人员可以快速看到用于测试的AI模型缺点以及改进方式。
Manifold利用所谓的聚类算法(k-Means)将预测数据,根据其性能相似性分成多个段。该算法通过其KL散度对特征进行排名,KL散度是两个对比分布之间差异的度量。一般而言,在Manifold中,较高的发散度表示给定的特征与区分两个片段组的因子相关。
Manifold包括对多种算法类型的支持,包括常规的二进制分类和回归模型。在可视化方面,它可以提取数字和分类以及地理空间要素类型。它与Jupyter Notebook集成在一起,Jupyter Notebook是为数据科学家和ML工程师使用最广泛的数据科学平台之一,并且具有交互式数据切片和基于每个实例的预测损失和其他特征值的性能比较。
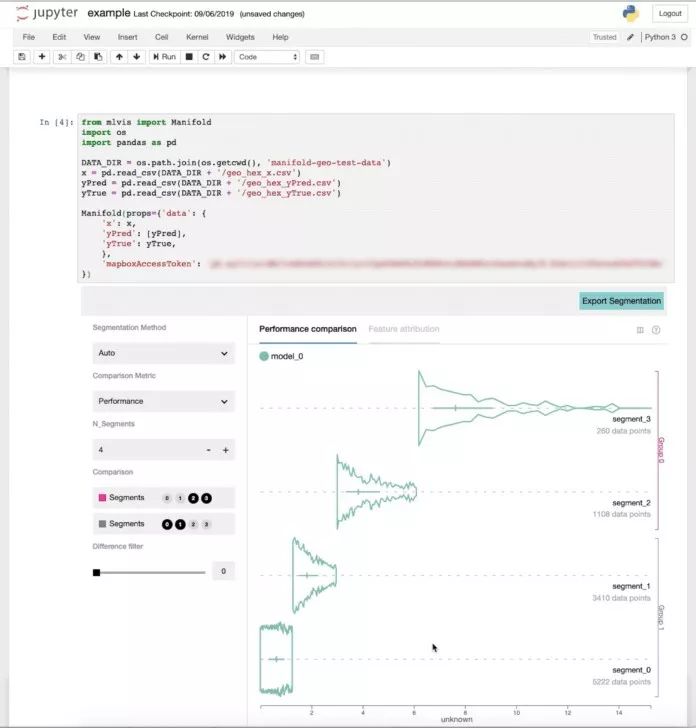
Uber还添加了各种功能在Manifold中,使AI模型的调试过程更加容易,功能如下:
-
支持与模型无关的通用二进制分类和回归模型调试:用户可以分析和比较各种算法类型的AI模型,从而使他们能够区分各种数据片的性能差异。
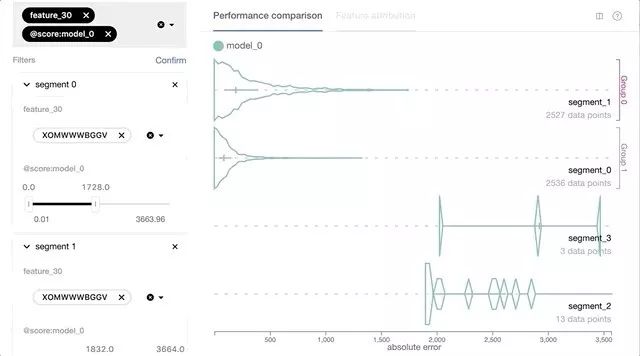
-
对表格化要素输入的可视化支持,包括数字,分类和地理空间等类型:通过每个数据切片的特征值分布信息,使用户可以更好地了解某些性能问题的潜在原因,例如:模型的预测损失与其数据点的地理位置和分布之间是否存在关联。
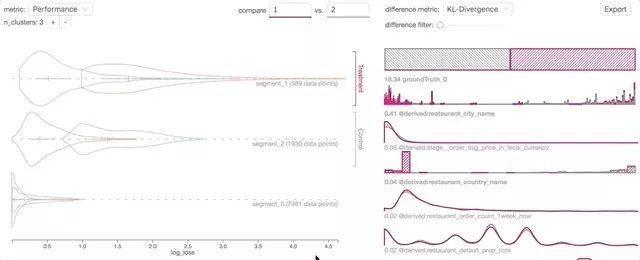
-
与Jupyter Notebook集成:通过这种集成,Manifold将数据输入作为Pandas DataFrame对象接受,并在Jupyter中呈现此数据的可视化。由于Jupyter Notebook是数据科学家和ML工程师使用最广泛的数据科学平台之一,因此该集成使用户可以在不中断正常工作流程的情况下分析其AI模型。
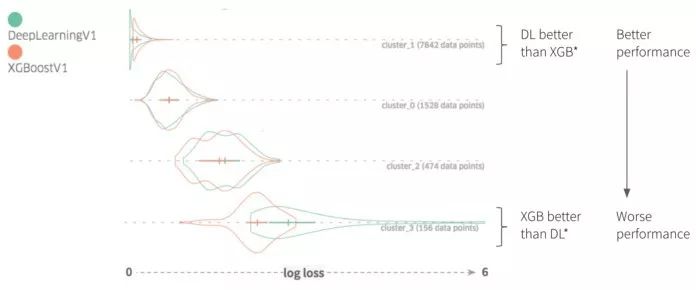
-
基于每个实例的预测损失和其他特征值的交互式数据切片与性能比较:用户将能够基于预测损失、地面真实性或其他感兴趣的特征对数据进行切片和查询。该功能将使用户能够通过通用的数据切片逻辑快速验证或拒绝其假设。
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > Uber开源Manifold,一款可视化AI模型调试工具
heng.png)
 达观助手智能写作产品正式发布,全面提升写作能力!
达观助手智能写作产品正式发布,全面提升写作能力! 生成式AI为何不完全适用当下B2B行业?
生成式AI为何不完全适用当下B2B行业? Gartner:ChatGPT只是开始,企业生成式AI的未来
Gartner:ChatGPT只是开始,企业生成式AI的未来 中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国