

导读
如何把你的人工智能想法转化为可用的软件。

建立一个 AI PoC 是困难的。在这篇文章中,我将解释我的思维过程,使我的人工智能 PoCs 成功。
“我的闹钟能不能利用交通信息及时叫醒我去上班?”我们都想过求助于人工智能来解决我们的一个问题。概念证明(PoC)的目标是测试是否值得在其中投入时间。构建 PoC 是困难的,但构建 AI PoC 则更加困难,因为它需要大量的技能。
在构建 AI PoC 时,数据科学只是工作的一小部分,但它是最重要的技能之一。很容易找到一些非常好的教程来教你如何解决一个特定的任务,如何构建一个检测算法来停车入库。如何部署一个 flask app 到云上。但是,为你的特定问题设计一个解决方案要困难得多,这主要是因为你需要后知后觉地将问题重新组织成标准化的任务。
在这篇文章中,我将解释我实现这一目标的方法。
首先,我将回顾一下人工智能系统是什么样子的。然后,我将描述我设计一个人工智能的 3 个步骤的过程。最后,我们将看到两个示例,一个简单的示例和一个完整的带有 python 实现的示例。
人工智能系统概述
作为一个例子,我将使用一个分类文件的系统来说。它回答的问题是,“这是什么类型的文件?答案是类似于“电子发票”或“待办事项”这样的类。
AI 工作流程包含 5 个步骤:
-
收到问题: “这是什么类型的文件? ” -
在用户或上下文中添加补充数据: “用户拥有什么类型的文件? ” -
使用数据回答问题: “这个文件属于哪种类型? ”,"这是能源发票" -
存储结果: 添加新文件到数据库 -
回答客户的问题: “这是能源发票”
你可以把它分成 3 个任务或语义块:
-
处理客户:接受问题,让他等待……
示例:HTTP 服务器
-
数据调取:与“公司知识库”沟通,增加或接收相关数据。
与数据库的通信
-
AI 部分:回答这个问题的 AI 本身,以及上下文。
例子:专家系统,支持向量机,神经网络…

你可以在网上找到关于如何架设你的服务器或数据调取层的教程。Python 中最简单的 AI PoC 解决方案是使用 Flask 和 SQL 数据库,但这在很大程度上取决于你的需要和你已经拥有的东西。我们将专注于设计 AI 本身。
设计 AI 部分
人工智能任务可能涉及多个异构输入。例如,用户的年龄和位置或整个电子邮件讨论。
人工智能的输出取决于任务:我们想要回答的问题。人工智能有很多不同的任务。在下面的图片中,你可以看到一些常见的计算机视觉任务。

一旦你从标准化的输入和任务中走出来,想办法构建一个人工智能就会变得很复杂。
为了让我了解构建 AI 的复杂性,我使用了一个 3 步的过程。
步骤 1:浏览相关的输入
首先,收集你觉得能够回答手头任务的所有输入,并选择在大多数情况下能够自给自足的输入。
在测试人工智能想法时,很容易变得贪婪,并考虑包含大量输入的解决方案:例如,用户的位置可能会让我了解他们的下一封电子邮件是什么。事实是:人们很容易迷失在各种不同含义或性质的输入中,最终什么也得不到。
在建造你的 AI 时,坚持简单的,自给自足的输入。
步骤 2: 数据向量化
第二步是对这些输入进行预处理,使其可用于各种算法。在某种程度上,每一个 AI 过程都要经过一系列的步骤来获得一个向量表示。
这个过程非常简单,比如计算单词在文档中出现的频率,或者直接使用图像像素的值。它也可以变得非常复杂的多层预处理。

输入可以是非常不同的:不同的大小、颜色比例或图像格式。请记住,这里的思想是构建所有输入的有意义的、规范化的表示。
构建规范化的输入和有意义的表示。
步骤 3:处理向量
第三步是考虑输出和如何实现输出的时刻。
与输入一样,输出也需要“向量化”。对于分类,它很简单:按类划分一个字段。
然后,我们需要找到从输入向量到输出向量的方法。最后,这是我们开始寻找 AI 时学到的第一件事。它可以涉及到一些简单的任务,比如找到最近的向量或最大值,也可以涉及到更复杂的任务,比如使用巨大的神经网络架构。
大多数任务,如回归、分类或推荐,都有详细的文档记录。对于 PoC,最简单的操作是使用一个预先实现的算法库,如scikit-learn[1]并进行测试。

找一些简单的和预先实现好的算法。
一个直接的例子
任务:文本是法语还是英语?
解决方案:
步骤 1:浏览相关输入。如果没有任何源或其他元数据,文本是惟一可能的输入。
步骤 2:向量化数据。向量化的一个简单方法是计算英语单词和法语单词的数量。我们将使用特定语言中最常用的单词。它们被称为停用词:the, he, him, his, himself, she, her…
步骤 3:处理向量。然后,我们可以选择使用这两个值中最高的值进行分类,以获得二进制输出:True 或 False。
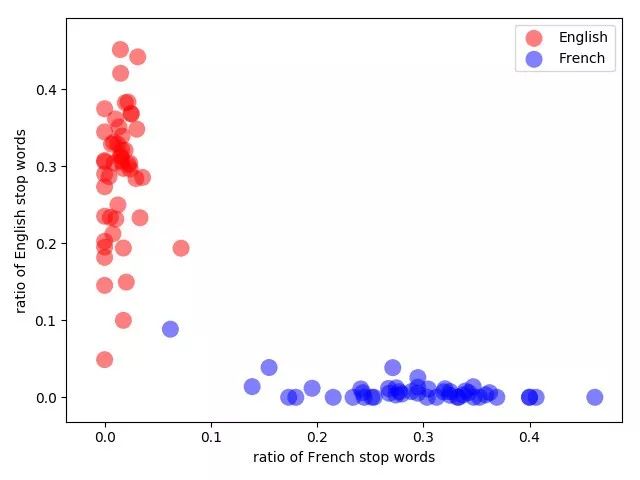
维基百科中法语和英语的页面按照词缀比例随机划分。蓝色的异常值是关于 Ferroplasmaceae 的法语页面,遗憾的是,它包含的英语参考文献比法语句子还多。
构建人工智能通常是人类专长(商业知识)和计算机智能(机器学习)的混合。在这个例子中,由于法语和英语的停用词,我使用了人类的专业知识来选择如何构建我的向量。我也可以使用机器学习来训练一个模型,要么构建一个相应的向量(步骤 2),要么学习更复杂的向量的分类(步骤 3)。
一个更复杂一点的问题
在一次会议上,我与一个从事数字安全项目的人交谈。他告诉我,他想帮助他的用户对他们的个人文档进行分类和排序:合同、账单、文件……他注意到,随着存储的内容越来越多,文件夹树也越来越复杂,人们往往会对自己的文档进行错误的分类。找到他们想要的内容也变得更加困难。搜索引擎只是在“修补”问题,而不是消除根本原因:只有在知道准确信息的情况下才能找到文档,而文件夹仍然很混乱。
那么我们该如何解决这个问题呢?
注:我真的开发了这样一个系统:https://github.com/Wirg/digital-safe-document-classification
阐明 PoC 的思想并定义其范围
我们将设计一个用户界面,用户可以上传一个文档,然后提示用户这个文档最适合的文件夹是什么。我们希望支持这些类型的文件:txt、text、markdown 和 pdf。
“data_to_read”是我放想要阅读的文章的文件夹。Work 是一个文件夹,里面有我以前的学校报告(主要是数据科学项目)。在 15 个文件夹中选择 2 个。具体实现:https://github.com/Wirg/digital-safe-document-classification。
我们想要提示用户的是他们当前的文件夹,而不是旧的或来自其他人的文件夹:答案必须是特定于用户和特定于时间的。
步骤 1:浏览相关的输入
首先,我们需要知道用户的文件夹,否则我们将无法回答。要做出选择,我们可以使用:
-
文件的内容 -
添加时间: 有些账单可能是按月支付的,有些任务可能大部分是在特定时间内完成的 -
文件名和类型: " energy_invoice_joe_march.pdf "、“pdf”
在我们的例子中,最可靠的输入可能是文档的内容。我们将使用上传的文档和用户文件夹的内容作为比较。我们来关注一下。
步骤2: 输入向量化
现在,我们有不同的输入格式:pdf、markdown、text、txt…我们可以直接处理 markdown 和其他文本格式的文件内容。但是我们必须处理 pdf 文件,才能像其他文件一样使用它们。
我通过谷歌搜索找到了这里使用的工具 Pdftotext。它是有效的,但有一个巨大的缺点,它不执行光学字符识别(OCR)。这意味着它将读取大多数 pdf 文件,但无法读取由图像或扫描件创建的文件。为了解决这个问题,我可以使用像 Tesseract 这样的替代方法,但是我不会在这个例子中使用。
我们想把文本转换成向量,让我们来看看scikit-learn[2]。我们找一个文本向量化的工具,我们找到一个文本的特征提取包。这正是我们要找的。它有两个向量化工具:一个基于单词计数,另一个称为 TfidfVectorizer,我们使用的就是这个。

Tfidf 表示词频和逆文档频率。它基本上是数字,但用了一种更聪明的方法。其思想是,我们不只是计算单词的数量,而是通过计算单词的频率,并将其与文档中的单词数量进行比较,从而了解文档中某个单词的重要性:词频(term frequency, TF)。然后,我们将其频率与文档数量进行比较。文档中出现的频率越少,它对文档的影响就越大:逆文档频率(IDF)
步骤 3:处理向量
我们需要一个最佳文件夹的列表作为最终输出。将文件夹名映射到数字很简单。但是我们不能得到一个简单的标准化输出向量因为输出向量的大小会改变。实际上,文件夹的数量在很大程度上取决于用户及其当前文件夹。由于这个原因,我们不能使用固定数量的类的普通分类算法。我们需要每次都对模型进行重新训练,并为每个用户构建一个模型,或者为所有用户构建一个大型模型。
但是我们已经在向量化过程中加入了“智能”。因此,我们将采取另一种方法,更类似于搜索引擎:对上传的文档、文件夹中已经存在的文档进行矢量化,并比较结果向量。
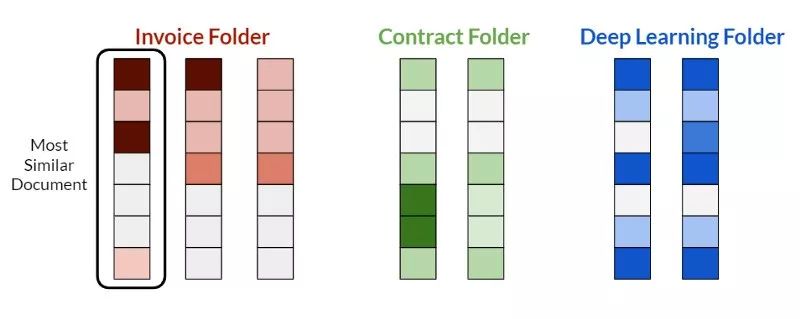
为了找到最好的文件夹,我们寻找与上传文档最匹配的文档。
我们找到向量表示与上传文档最相似的文档,并将通过它找到原始文件夹。
使用余弦相似性查找最佳文件夹。
总而言之,解决 AI 问题可以简化为以下 3 个步骤:
-
首先,浏览相关输入 -
其次,向量化数据 -
第三,处理向量
我希望它能帮助你实现你的人工智能想法。
英文原文:https://www.sicara.ai/blog/2019-03-29-how-build-succesful-ai-poc
特别声明:
文章来源:AI公园(AI_Paradise)
作者:Arnault
编译:ronghuaiyang
原文链接:https://mp.weixin.qq.com/s/pAUOCvUPEHf-EwTGuG04YA
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 如何构建一个成功的AI PoC(Prove of Concept)
heng.png)
 达观助手智能写作产品正式发布,全面提升写作能力!
达观助手智能写作产品正式发布,全面提升写作能力! 生成式AI为何不完全适用当下B2B行业?
生成式AI为何不完全适用当下B2B行业? Gartner:ChatGPT只是开始,企业生成式AI的未来
Gartner:ChatGPT只是开始,企业生成式AI的未来 中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
中国何时能有ChatGPT?“现象级”产品背后的AI技术发展与展望
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国