

用UiPath的DataScraping(数据抓取)功能,鼠标点击几下,就可以实现抓取浏览器、应用程序或文档界面结构化数据,可谓功能强大!
抓取方式分为两种:a、自动抓取整张表内容;b、按需求抓取需要的列内容及列内容的URL(超链接网址)。
这个功能用得不多,不过还是很好用的,而且有点技巧在里面,特此介绍。
数据抓取使您可以将浏览器、应用程序或文档中的结构化数据提取到数据库,.csv文件甚至Excel电子表格中。
注意:
建议在Internet Explorer 11及更高版本、Mozilla Firefox 50或更高版本或最新版本的Google Chrome上使用该功能。
结构化数据是一种高度组织化的特殊信息,以可预测的方式呈现。
例如,所有Google搜索结果都具有相同的结构:顶部的链接,URL的字符串和网页的描述。
这种结构使Studio可以轻松提取信息,因为它始终知道在哪里可以找到信息。
1. 打开要从中提取数据的网页、文档或应用程序界面,单击“ 设计”选项卡中“ 数据收集”按钮,

打开数组抓取向导:
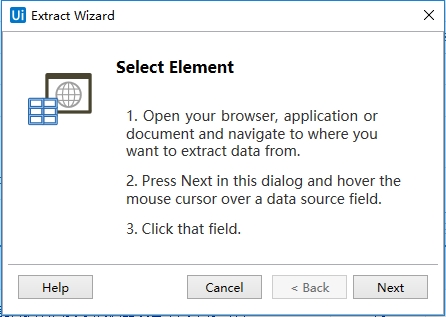
点击Next,然后选择要抓取的数据的第一个单元格里面的内容:

然后,Studio会自动检测您是否指示了表格单元格,并询问您是否要提取整个表格:
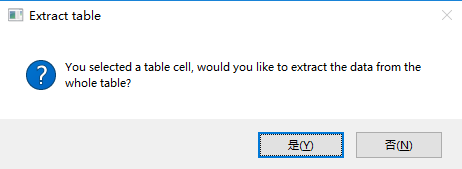
-
如果单击“ 是”,进入自动抓取方式,“ 提取向导”将显示所选数据所在的表的所有数据预览:
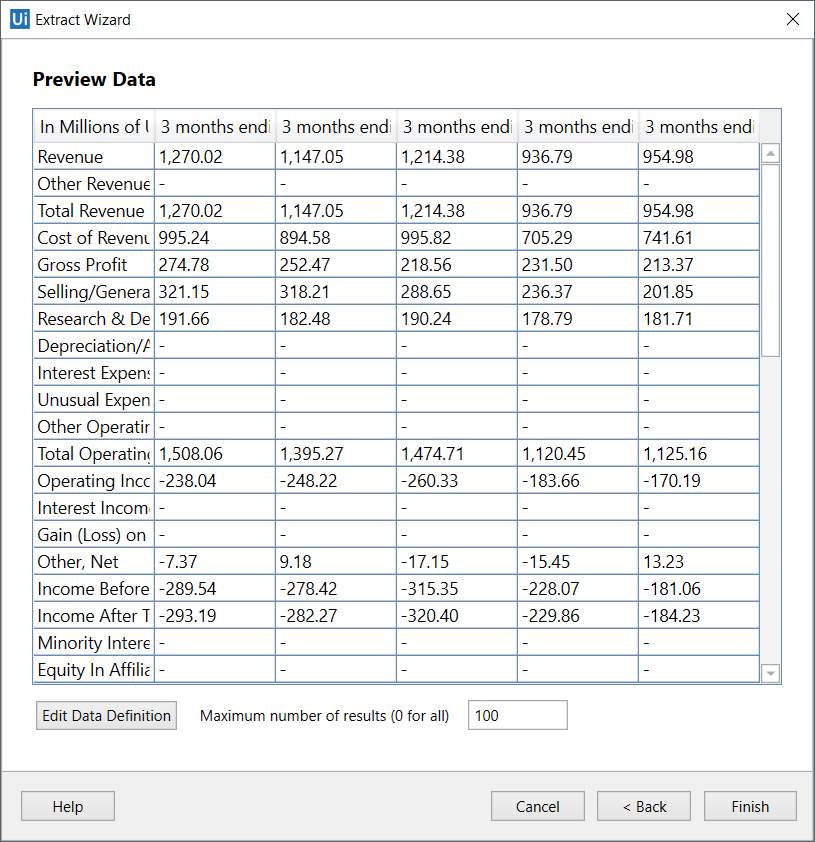
再点击Finish,进入第5步。
-
如果单击“ 否”,则进入按需的抓取模式,出现下面的界面:

点击Next,回到要抓数据的界面,点击同类型或同列第2个数据,
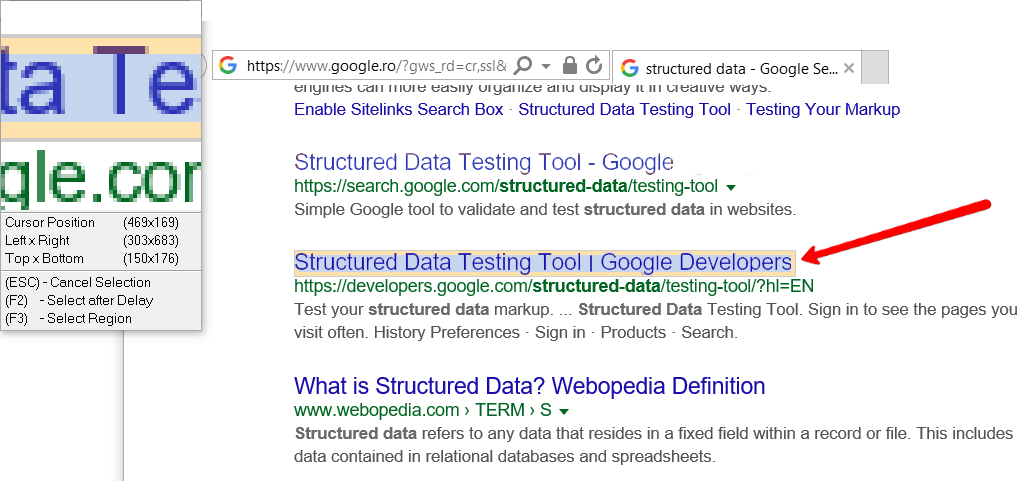
选择后,Studio可以推断出信息的模式,进入下面的界面。
2. 自定义列标题,然后选择是否提取URL。
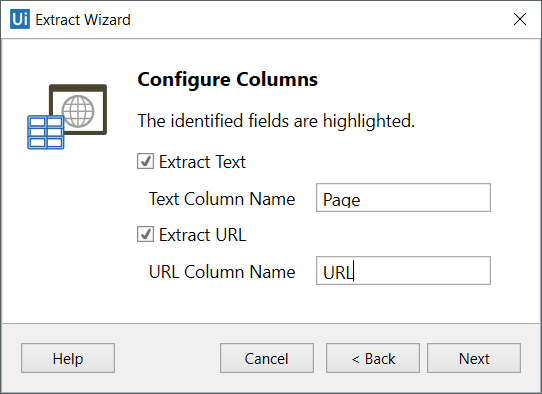
3. 点击Next,进入预览数据界面,编辑要提取的最大结果数,然后更改列的顺序:
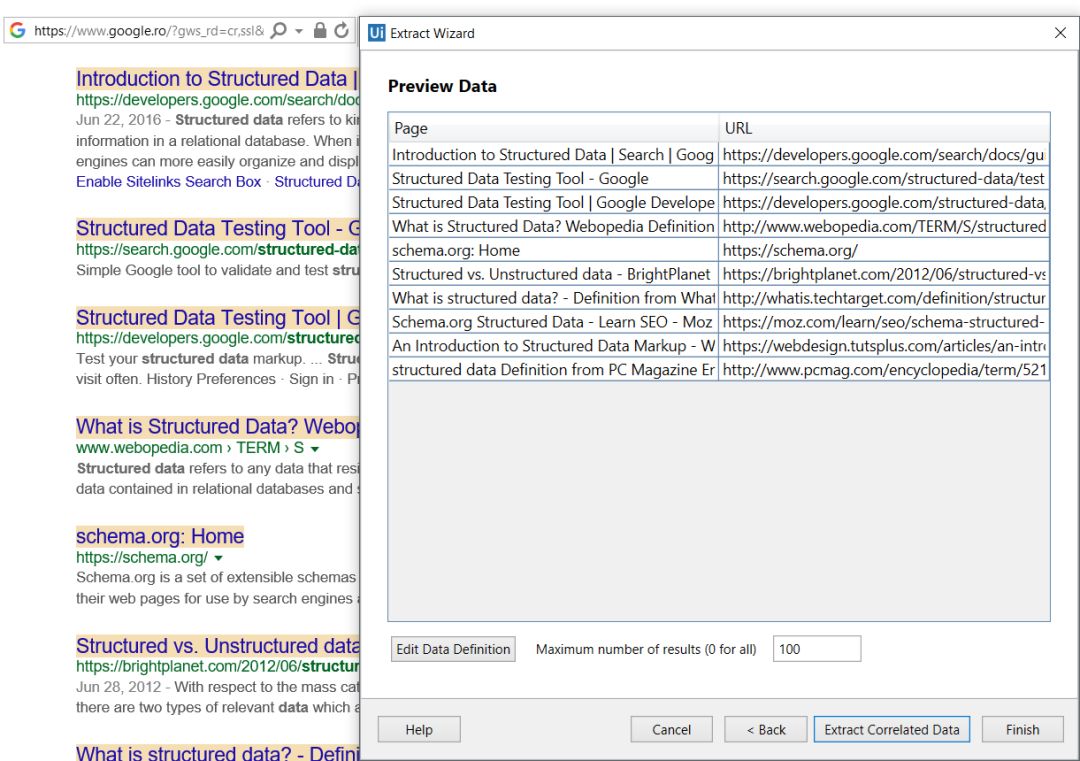
4. (可选)如果还需要抓取其他列,单击提取相关数据(Extract Corralted Data)按钮。这使您可以再次执行“ 提取向导”(也是需要两次点击同一类型数据),以提取其他信息并将其添加为同一表中的新列。
5. 指示网页,应用程序或文档中的“ 下一步”(Next)按钮(如果要提取的信息跨越多个页面)。
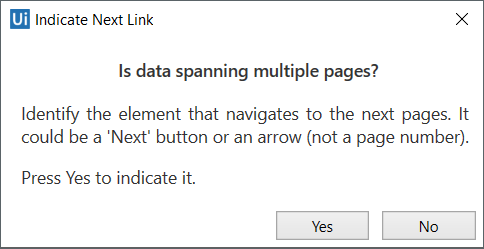
这里需要告诉想到,是否需要它帮你点击下一页,以便收集所有的数据。如果选择Yes,需要点击“下一页”按钮,否则点击No,完成向导。
完成向导后,Studio中会生成一个序列:
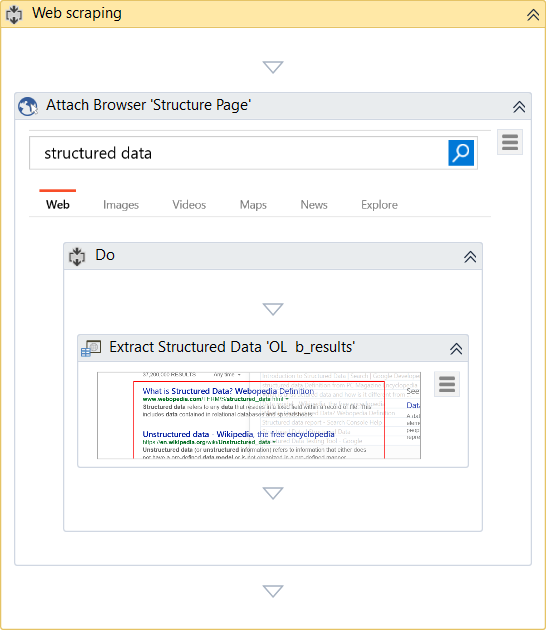
数据抓取始终会生成一个容器(“附加浏览器”或“附加窗口”),该容器带有用于顶层窗口的选择器,以及带有部分选择器的“ 提取结构化数据”活动,从而确保正确识别要抓取的应用程序。
此外,“提取结构化数据”活动还带有一个自动生成的XML字符串(在ExtractMetadata属性中,其中自动抓取生成的内容很简单,手动一列一列抓取的内容稍微复杂点,好在都是自动生成,无需太多关注),该字符串指示要提取的数据。
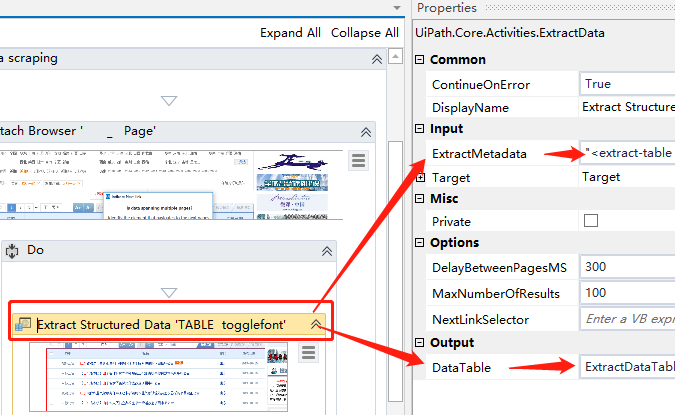
最后,所有已抓取的信息都存储在你定义的DataTable变量(如上图的ExtractDataTable)中,接下来,您就可以使用变量ExtractDataTable来保存到数据库、csv文件或Excel电子表格。
网页文件是用html写的,网页看见的文字,可能被裹了很多层用于格式的代码,如果抓取到不合适的层,可能抓取不到需要的URL,举例如下:

抓取包裹文字所在的层,可以抓到URL,不在其被包裹的层,例如单元格。
如果需要抓取URL,只能用第二种方式(按需取列)。
特别声明:
文章来源:“柴班说”微信公众号
作者:柴娟伟
RPA中国推荐阅读,转载此文是出于传递更多信息之目的。如有来源标注错误或侵权,请联系更正或删除,谢谢。
未经允许不得转载:RPA中国 | RPA全球生态 | 数字化劳动力 | RPA新闻 | 推动中国RPA生态发展 | 流 > 借助UiPath RPA,轻松搞定数据抓取
heng.png)
 UiPath学院| 培训平台与认证项目再升级,加速提升员工的RPA技能!
UiPath学院| 培训平台与认证项目再升级,加速提升员工的RPA技能! 经验分享| 从小白到考级 五位同学的RPA修炼手册
经验分享| 从小白到考级 五位同学的RPA修炼手册 如何利用RPA跟踪物流?
如何利用RPA跟踪物流? UiPath StudioX,自动化从未如此简单
UiPath StudioX,自动化从未如此简单
















热门信息
阅读 (14728)
1 2023第三届中国RPA+AI开发者大赛圆满收官&获奖名单公示阅读 (13753)
2 《Market Insight:中国RPA市场发展洞察(2022)》报告正式发布 | RPA中国阅读 (13055)
3 「RPA中国杯 · 第五届RPA极客挑战赛」成功举办及获奖名单公示阅读 (12964)
4 与科技共赢,与产业共进,第四届ISIG中国产业智能大会成功召开阅读 (11567)
5 《2022年中国流程挖掘行业研究报告》正式发布 | RPA中国